In order to model something, you first need to measure it. You need to be able to assign a number to an emotion. Since emotions are already either positive or negative, we already have a natural way to assign them values. Most of us can read a text and agree on whether it has a positive or negative tone. But can we automatically assign a number to emotional content on the basis of this assessment? Frank and his colleagues have adapted the software SentiStrength, which claims to be an algorithm to do exactly this. You feed it in a sentence and out pops a ranking. I put in the last sentence of the previous paragraph in to the online version and got negative score -2 for the words 'skeptical' and 'emotional' along with a positive score of 2 for 'interested'. Good to see I was emotionally neutral going in to the seminar.
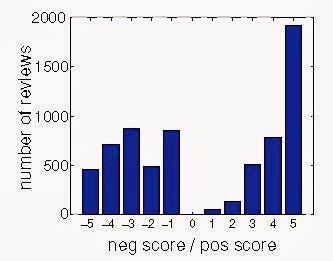 |
| Review sentiment distribution for 'Harry Potter and The Deathly Hollows' |
In one study, Garcia & Schweitzer looked at book reviews left on the Amazon website. There was a typical distribution of negative and positive emotions in these reviews (pictured on the right) where positive comments were typically extremely positive and negative criticism was varied. The time pattern of review writing varied, with some books building up a review base over time and others (such as Harry Potter) being hyped from the start.
Things get even more interesting
when Frank and his colleagues looked at online chat rooms. They examined how long it took between interactions and whether the reactions were
positive or negative. They found a
common distribution for the times between posts, which was independent of the
topic. They concluded that people were surprisingly positive in their
online interactions, even though previous studies had suggested that discussion
is generated by negative opposing opinions. When online, people spend a lot of
time being nice to each other! Not just pressing the like button, but also in
constructive agreement.
 |
| Time series of emotions in an online chat room. |
In another part of their work, Frank and
his colleagues argue that “positive words carry less information than negative words”, so I better be a bit critical. In the presentation, and the papers I have
looked at since, I think a model comparison to the dynamics of the conversations and
exchanges is missing. The model proposed captures the rate at which people
comment and the positive/negative content of what they say. But the comparison
to data is mainly at the level of time between posts or overall distribution of
sentiment, rather than looking at the positive/negative interactions. I would
like to see something down the lines of James Murray and co-workers on the Mathematics of Marriage. Here there is a description of how couples get in to
negative/positive spirals and predictions to how this bodes for the futures of the relationships
of the couples involved. Murray’s work lacks thorough validation against data, and maybe
it becomes too complicated once the fast amount of chat room data is put in to
a model, but I would like to see more of these interaction dynamics. Maybe this
is in some of the work and I have just missed it? Or maybe it is just too difficult at present? But I would be interested to
see what can be done.
No comments:
Post a Comment